- RDB는 평소에 사용하며 알고 있는 지식이었지만, No-SQL을 처음 접하여 자세히 알고자 조사하였습니다.
- 이 글에서는 No-SQL이 무엇인지, 특징, 장단점, 종류와 차이점에 대해 알고자 작성하였습니다.
RDBMS (관계형 데이터베이스, Relational Database)
- 표 형태의 데이터를 사용
- 데이터 간의 관계를 표현하기 위해 여러 테이블을 사용
- 트랜잭션 관리
- RDBMS는 트랜잭션을 사용하여 여러 작업을 논리적으로 묶어 일관성을 유지
- 성공적으로 완료되거나 실패할 경우 롤백하여 일관성 보장
- 자세한 내용은 ACID 원칙과 트랜잭션 관리 방법 블로그를 참고 해주세요.
장점
- 데이터 일관성 및 무결성 보장
- ACID(Atomicity, Consistency, Isolation, Durability) 특성을 제공하여 데이터 일관성과 무결성을 보장합니다.
- 트랜잭션 처리를 통해 데이터베이스 상태를 안정적으로 유지할 수 있습니다.
- 구조화된 데이터 저장
- 테이블 형태로 데이터를 구조화하여 저장하므로, 데이터의 구조와 관계가 명확하게 정의되어 있습니다.
- SQL 사용으로 편리한 데이터 조작
- SQL(Query Language)을 사용하여 데이터를 쉽게 조작할 수 있습니다.
- SQL은 직관적이며 표준화되어 있어 다양한 데이터 조작 작업을 수행할 수 있습니다.
- 데이터 중복 최소화
- 정규화를 통해 데이터 중복을 최소화하고, 외래 키를 활용하여 데이터 간의 관계를 유지함으로써 일관성을 유지하고 데이터의 무결성을 강화합니다.
단점
- 고정된 스키마 구조
- 고정된 스키마를 갖고 있어, 데이터 모델이 변경되면 스키마를 업데이트해야 합니다.
- 복잡한 조인
- 다수의 테이블이 관계를 맺고 있을 때 조인 연산이 복잡해질 수 있습니다.
- 이는 성능 저하를 가져올 수 있습니다.
관계형 데이터베이스(RDBMS)가 Scale-out이 힘든 이유
- RDBMS는 Scale-out을 설계하고 만들어지지 않음
- Partitioning(Sharding) - 분할에 의한 확장을 사용할 경우
- Read만큼 Write도 확장할 수 있지만 애플리케이션 레이어에서 파티션 된 것을 인지하고 있어야 한다.
- RDBMS의 가치는 관계에 있다고 할 수 있는데 파티션을 하면 이 관계가 깨져 버리고 각 파티션된 조각 간에 조인을 할 수 없기 때문에 관계에 대한 부분은 애플리케이션 레이어에서 책임져야 한다.
- 서버 확장 방법은 Scale-out과 Scale-up이 있으며 정확한 차이는 Scale-up VS Scale-out 블로그를 참고해주세요.
No-sql (비관계형 데이터베이스, Not Only SQL)
- DOCUMENT 형 데이터베이스 관리 시스템(DBMS)
- 데이터를 조직하는 자료구조
- 리스트, 해시, 트리, 그래프 등을 사용
- 각 자료 구조는 자체적인 특징과 장단점을 가지고 있으며, 사용되는 상황에 따라 적절한 구조를 선택
- 기존 RDBMS(Realational DateBase Management System) 형태의 관계형 데이터베이스가 아닌 다른 형태의 데이터 저장기술을 의미하여, 관계형 데이터베이스의 한계를 극복하기 위한 데이터 저장소의 새로운 형태
- NoSQL 데이터베이스는 개발자가 엄청난 양의 비정형 데이터를 저장할 수 있도록 지원하여 뛰어난 유연성을 제공
- CAP 이론 중 일반적으로 AP(가용성과 분할 내성)에 해당
장점
- 데이터 간의 관계를 정의하지 않음
- Join 연산 불가능
- Lookup으로 가능하긴 하나 Join 연산과 다름
- 두 테이블이 아닌 하나의 테이블에서 데이터를 찾는 개념
- 대용량의 데이터를 저장할 수 있음
- 페타바이트(1,000TB) 급의 대용량 저장공간
- 분산형 구조
- 여러 곳의 서버에 데이터를 분산 저장 특정 서버 장애 발생 시 데이터 유실 혹은 서비스 중지가 발생하지 않도록 함
- 고정되지 않은 테이블 스키마를 가짐
- 테이블 스키마가 유동적
- 데이터 칼럼이 각기 다른 이름과 다른 데이터 타입을 갖는 것이 가능
- 비정형 데이터 구조 설계로 설계 비용 감소
단점
- 데이터 업데이트 중 장애가 발생시 데이터 손실 확률이 있음
- 분산 데이터베이스에서의 장애 - 복제된 데이터를 읽기 전까지 일시적인 데이터 불일치
- 트랜잭션 도중 장애 - 트랜잭션이 롤백되거나 데이터 일관성이 깨짐
- 네트워크 문제 - 업데이트된 데이터 다른 노드로 전달이 안됨
- 많은 데이터를 사용하려면 충분한 메모리 필요
- 인덱스 구조가 메모리에 저장되기에 충분한 메모리가 필요
- 데이터 일관성이 보장되지 않음
- NoSQL 데이터베이스는 가용성(Availability)과 분할 내성(Partition Tolerance)을 중시
CAP 이론
CAP 이론은 이론적으로 데이터베이스가 CAP 세 가지 성질을 모두 만족시키는 것이 불가능하며, 최대 2가지만 동시에 보장할 수 있다는 이론
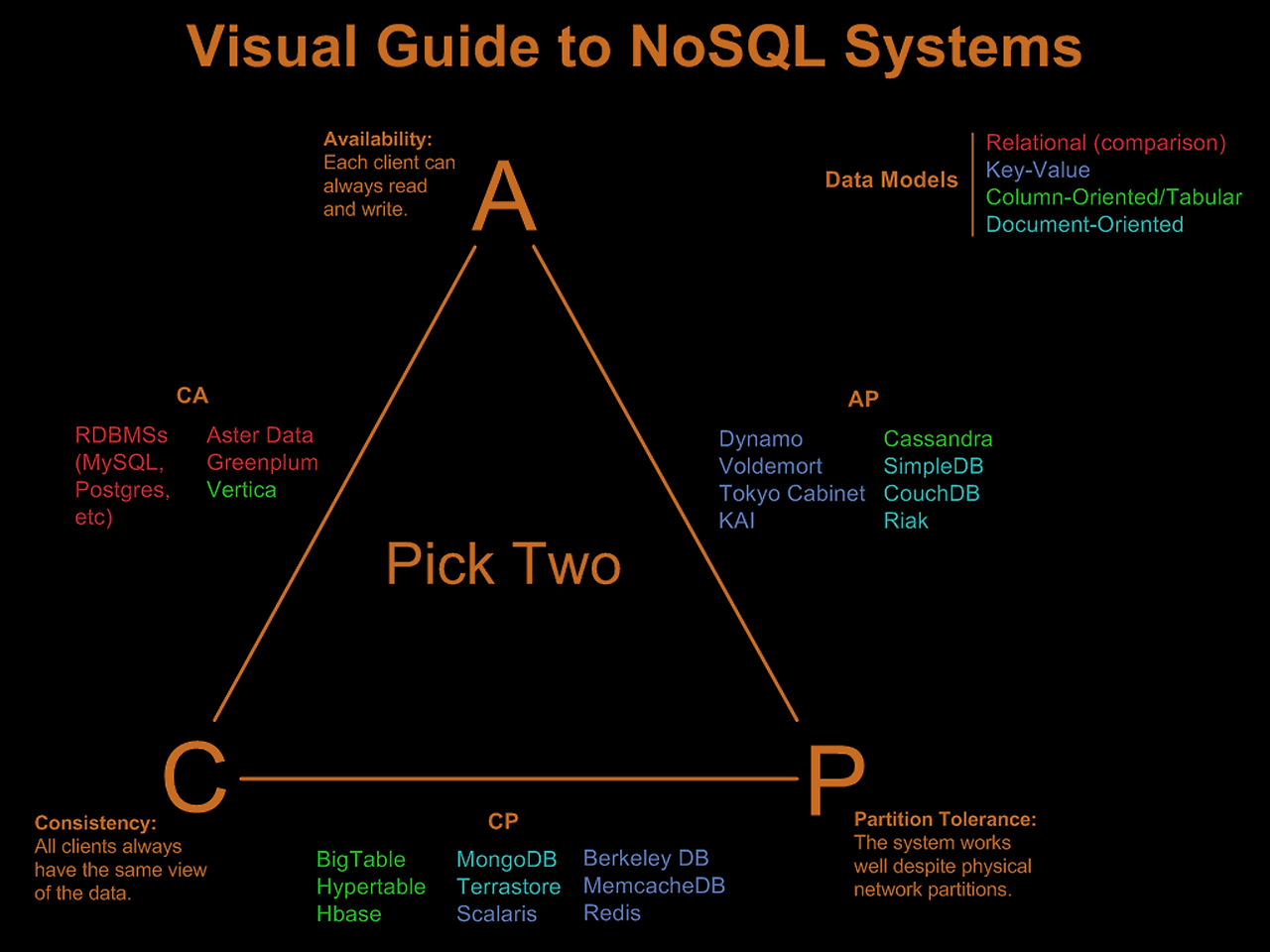
- Consistency, 일관성
- 모든 클라이언트는 데이터베이스에서 동시에 같은 데이터를 접근해야 한다.
- 모든 읽기와 쓰기 작업은 언제나 가장 최근에 업데이트된 데이터를 반환해야 합니다.
- Availability, 가용성
- 가용성은 모든 요청에 대해 응답이 있어야 합니다.
- 시스템에서 일부 노드가 실패하더라도 나머지 노드는 계속해서 응답할 수 있어야 합니다.
- Partition tolerance, 분할 내성
- 시스템이 일시적으로 네트워크의 문제로 인하여 노드가 정지되거나 메시지 전송이 지연되는 상황에서 정상적인 동작을 유지할 수 있어야 한다.
NoSQL의 종류
- Key-Value Database
- ex) Redis, Oracle NoSQL Database, VoldeMorte
- key-value로 저장되는 단순한 구조
- 속도가 빠르며 분산 저장 시 용이
- SCAN에는 용이하지 않음
- Wide-Column DataBase
- ex) Hbase, GoogleBigTable, Vertica
- 행마다 각각 다른 값과 다른 수의 스키마를 가짐
- 대량의 데이터의 압축, 분산처리, 집계 쿼리 및 쿼리 동작 속도, 확장성이 뛰어남

- Document Database
- ex) MongoDB, CouchDB, Azure Cosmos DB
- 테이블의 스키마가 유동적, 레코드마다 각각 다른 스키마를 가짐
- 보통 XML, JSON과 같은 DOCUMENT를 이용해 레코드 저장
- 트리형 구조로 레코드를 저장하거나 검색하는데 효과적

- Graph DataBase
- ex) Neo4j, BlazeGraph, OrientDB
- 데이터를 노드로 표현
- 노드 사이의 관계를 화살표로 표현
- 일반적으로 RDBMS보다 성능이 좋고 유연하며 유지보수에 용이
- Social network, Network diagrams 등에 사용

결과
- 이를 통해 NoSQL과 RDB 간의 장점과 단점을 비교하며, 차이를 이해할 수 있었습니다.
- 현재 프로젝트에서는 검색 API의 성능 향상을 위해 Redis을 선택하여 적용하게 되었습니다.
- CAP 이론에 대한 학습을 통해 각 데이터베이스 시스템의 특성을 파악하고, 프로젝트의 상황과 목적에 맞게 데이터베이스를 선택하는 중요성을 깨달았습니다.
느낀점
- 현재 Redis를 사용하고 있지만, 향후 상황과 목적에 따라 다른 No-SQL 데이터베이스를 도입하고자 합니다.
- 또한, 현재 프로젝트에서는 RDB을 중점으로 사용하였으나 향후 No-SQL을 중점으로 하는 프로젝트를 진행해보고 싶습니다.
- 서버를 증설할 때 Scale-out과 Scale-up 중 어떤 방법이 적절한지에 대한 궁금증이 생겼습니다. 이에 대해 자세히 조사하여 정리할 예정입니다.
참고
'데이터베이스' 카테고리의 다른 글
| 락(Locking) 메커니즘 (0) | 2024.03.09 |
|---|---|
| ACID 원칙과 트랜잭션 관리 방법 (0) | 2024.03.09 |
| Redis 설치 및 GUI 적용 (0) | 2022.11.14 |