JPA의 기본 동작 요약

EntityManager
- JPA에서 엔터티를 저장, 조회, 수정, 삭제하는 등의 데이터베이스와의 상호작용을 관리하는 인터페이스입니다.
- EntityManager를 통해 JPQL을 사용하여 쿼리를 실행하고, 엔터티 간의 관계에서 지연 로딩과 즉시 로딩을 관리합니다.
- 캐싱 기능을 통해 쿼리 및 엔터티 결과를 캐싱하고, flush 메서드를 사용하여 영속성 컨텍스트의 변경을 데이터베이스에 동기화할 수 있습니다.
- 엔터티의 생명주기를 관리합니다. 엔터티의 영속화, 준영속화, 삭제 등의 상태 변화를 추적하고 업데이트합니다.
- EntityManagerFactory를 사용하여 EntityManager를 생성하며, EntityManagerFactory는 애플리케이션의 생명주기 동안 공유되어야 합니다.
EntityManagerFactory
- EntityManagerFactory는 JPA에서 EntityManager를 생성하기 위한 인터페이스입니다.
- 일반적으로 애플리케이션이 시작될 때 EntityManagerFactory를 생성하고, 애플리케이션이 종료될 때 닫습니다.
- 데이터베이스 연결을 설정하고, 엔터티 매핑 정보를 로드하며, EntityManager을 생성하며, 다수의 데이터베이스와의 연결 및 다양한 엔터티 매핑 설정을 포함할 수 있습니다.
- 애플리케이션 전체에서 공유되므로, 모든 엔터티 매니저가 이를 통해 생성되고 관리됩니다.
자세한 내용은 JPA EntityManager의 Thread-safe 이해하기 을 참고해주세요.
Spring boot JPA
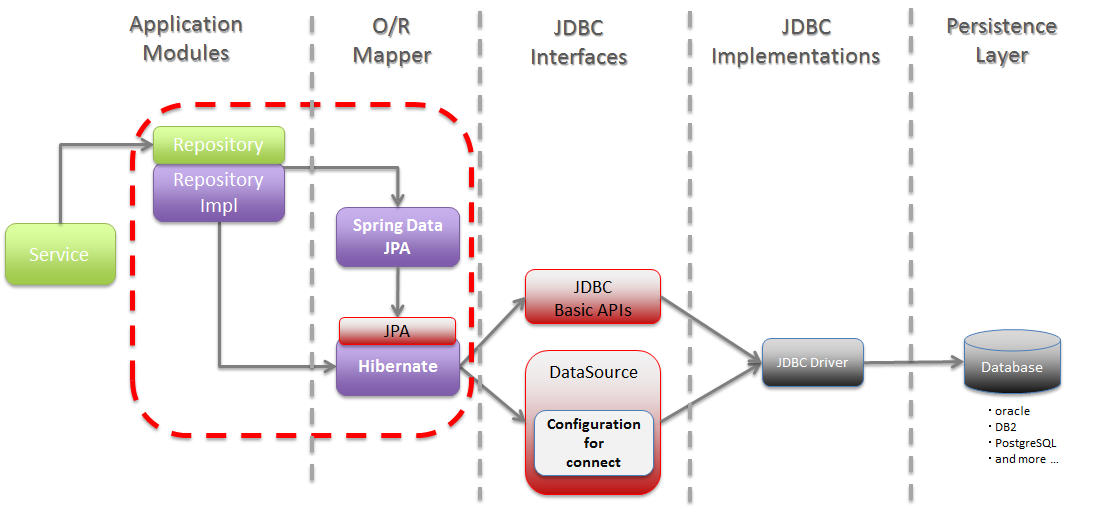
Spring Data JPA가 제공하는 JpaRepository 인터페이스를 활용하면 Spring Data JPA의 강력한 기능을 활용할 수 있습니다. JpaRepository에 정의된 메소드 네이밍 규칙을 따르면, 쿼리를 직접 작성하지 않고도 해당 메소드에 대한 쿼리가 자동으로 생성됩니다.
JpaRepository
- Spring Data JPA 프레임워크에서 제공하는 인터페이스
- CRUD(Create, Read, Update, Delete) 기능을 제공하며, 개발자가 간단한 메소드 선언만으로도 데이터베이스 작업을 수행
- 데이터를 페이지로 나누거나 정렬하여 반환할 수 있는 기능을 제공(Paging, 정렬 기능 제공)
쿼리 생성 과정 및 명명 규칙
- 메소드 이름 분석
- JpaRepository에서 제공하는 메소드 명명 규칙에 따라 메소드의 이름을 분석합니다.
- 메소드 이름은 해당 동작을 나타내는 동사와 조회 대상을 지정하는 명사 또는 속성 이름
- 메소드 이름을 분석하여 쿼리의 조건절을 결정하고, 필요에 따라 정렬(order by)이나 제한(limit) 조건을 추가합니다.
- 메소드 이름 해석
- 메소드 이름을 해석하여 쿼리의 조회 대상이 되는 엔터티 클래스와 해당 속성을 식별합니다.
- JPQL 쿼리의 FROM 절과 WHERE 절을 생성하는 데 필요한 정보를 얻습니다.
- 예를 들어, 메소드 이름에 "findById"가 포함되어 있다면 해당 ID를 가진 엔터티를 조회하는 동작을 수행합니다.
- 쿼리 생성
- 메소드 이름을 해석하여 적절한 JPQL(Querydsl) 또는 네이티브 SQL 쿼리를 생성합니다.
- 생성된 JPQL 쿼리는 조회 대상 엔터티와 해당 속성을 기반으로 WHERE 절에 적절한 조건을 추가합니다.
- 메소드의 반환 타입과 매개변수 등을 고려하여 적절한 쿼리를 생성합니다.
- 실행
- 생성된 JPQL 쿼리는 Spring Data JPA에 의해 데이터베이스로 전송되어 실행됩니다.
- 데이터베이스는 JPQL 쿼리를 해석하여 해당하는 엔터티를 조회하고, 결과를 반환합니다.
위와 같은 순서를 바탕으로 쿼리를 생성 및 실행하게 됩니다.
- ex) boolean existsByUserId(String userId);
- "existsByUserId"는 특정 조건을 만족하는 엔터티가 존재하는지 확인하는 동작을 수행합니다. 해당하는 "userId" 속성을 가진 엔터티가 존재하는지 여부를 확인합니다.
JpaRepository 인터페이스를 통해 개발자는 자동으로 생성되는 쿼리 뿐만 아니라 직접 쿼리를 작성하여 사용할 수 있습니다. 이때는 @Query 어노테이션을 사용하여 직접 SQL 쿼리를 작성(JPQL)할 수 있습니다. 이를 통해 개발자는 자유롭게 원하는 쿼리를 작성하고 실행할 수 있습니다.
JPQL (Java Persistence Query Language)
- JPA에서 사용되는 객체 지향 쿼리 언어
- 데이터베이스 테이블이 아닌 엔티티 객체에 대한 쿼리로 작성
- JPA 구현체(예: Hibernate, EclipseLink)가 데이터베이스 쿼리로 변환하고 실행
ex) 특정 가격 이상의 상품 조회
//Java
@Query("SELECT p FROM Product p WHERE p.price >= :price")
List<Product> findProductsAbovePrice(@Param("price") double price);
@Query 어노테이션을 사용할 때는 데이터베이스의 컬럼명이 아닌 해당 엔터티 클래스에서 선언한 필드명을 사용해야 합니다.
지연 로딩 (Lazy Loading)
- 연관된 엔터티를 실제로 사용할 때까지 데이터베이스에서 로딩을 지연시키는 전략
- 특징
- 연관된 엔터티는 프록시 객체로 대체되어 실제 사용 시에 데이터베이스에서 로딩이 발생함
- 최초 쿼리 실행 시 연관된 엔터티의 데이터를 로드하지 않고, 프록시 객체만을 가져옴
- 장점
- 최초 쿼리의 성능이 향상됨
- 실제로 필요한 시점에 데이터를 로딩하므로 효율적인 리소스 관리 가능
- 단점
- 연관된 엔터티를 사용할 때마다 추가적인 데이터베이스 쿼리가 발생할 수 있음
- 프록시 객체를 다루는 부가적인 복잡성이 발생할 수 있음
- ex) 게시글(Post)과 댓글(Comment)이 일대다(One-to-Many) 관계일 때
//Java
@Entity
public class Post {
@OneToMany(mappedBy = "post", fetch = FetchType.LAZY)
private List<Comment> comments;
}
@Entity
public class Comment {
@ManyToOne
@JoinColumn(name = "post_id")
private Post post;
}- fetch = FetchType.LAZY는 댓글 리스트가 실제로 사용될 때까지 로딩을 지연시키는 설정
- 과정
- 어플리케이션이 실행되면서 Post 엔터티를 조회하는 쿼리가 실행됩니다.
- 이때, Post 엔터티의 comments 필드는 fetch = FetchType.LAZY 설정으로 인해 초기에는 댓글 데이터를 로딩하지 않습니다.
- 어플리케이션이 댓글 데이터가 필요한 시점에 comments 필드에 접근하는 순간, JPA는 추가로 댓글 데이터를 가져오기 위한 쿼리를 실행합니다.
- 이로써 댓글 데이터는 필요한 시점에 로딩되고, 불필요한 데이터를 미리 로딩하지 않아 성능이 향상됩니다.
즉시 로딩 (Eager Loading)
- 연관된 엔터티를 즉시 로딩하여, 최초 쿼리 실행 시에 모든 데이터를 함께 가져오는 전략
- 특징
- 최초 쿼리 실행 시에 연관된 엔터티의 데이터까지 모두 로딩됨
- 데이터베이스에서 조인을 사용하여 관련된 엔터티를 모두 가져옴
- 장점
- 사용 시 추가적인 데이터베이스 쿼리가 발생하지 않아 성능 향상 가능
- 사용할 때마다 로딩이 필요 없어 프록시 객체를 다룰 필요가 없음
- 단점
- 최초 쿼리에서 불필요한 데이터를 로딩할 수 있어 성능 저하 가능
- 모든 연관된 엔터티를 항상 로딩하므로, 메모리 소모가 크고 효율이 감소할 수 있음
- ex) 게시글(Post)과 댓글(Comment)이 일대다(One-to-Many) 관계일 때
//Java
@Entity
public class Post {
@OneToMany(mappedBy = "post", fetch = FetchType.EAGER)
private List<Comment> comments;
}
@Entity
public class Comment {
@ManyToOne
@JoinColumn(name = "post_id")
private Post post;
}- fetch = FetchType.EAGER는 댓글 리스트를 게시글과 함께 즉시 로딩하도록 설정
- 최초 쿼리 실행 시 게시글과 연관된 모든 댓글을 함께 가져옵니다.
- 과정
- 어플리케이션이 실행되면서 Post 엔터티를 조회하는 쿼리가 실행됩니다.
- 이때, Post 엔터티의 comments 필드는 fetch = FetchType.EAGER 설정으로 인해 초기에는 댓글 데이터도 함께 로딩됩니다.
- 어플리케이션이 Post 엔터티를 조회하는 시점에 댓글 데이터도 함께 가져오기 때문에, 추가로 댓글 데이터를 가져오는 쿼리가 필요하지 않습니다.
- 다만 즉시 로딩은 관계된 엔터티를 한 번에 로딩하기 때문에 성능 저하의 가능성이 있습니다.

영속성 컨텍스트(Persistence Context)
- EntityManger로 엔티티를 저장하거나 조회하면 EntityManager는 영속성 컨텍스트에 엔티티를 보관하고 관리
- 엔티티를 데이터베이스에 저장(persist), 업데이트(merge), 삭제(remove)할 수 있습니다.
- 영속성 컨텍스트는 관리하는 엔티티의 변화를 추적하고, 한 트랜잭션 내에서 변화가 일어나면 엔티티에 마킹
- 트랜잭션이 끝나는 시점에 마킹한 것을 DB에 반영됩니다.
- 쓰기 지연을 함으로써 영속성 컨텍스트가 중간에서 쿼리들을 모았다가 한 번에 반영해 주니 DB와 네트워크 통신의 리소스 감소가 있습니다.
ex) 쓰기 지연
//Java
//JPA EntityManager를 사용하여 사용자를 로드합니다.
EntityManager entityManager = getEntityManager();
EntityTransaction transaction = entityManager.getTransaction();
transaction.begin();
User user = entityManager.find(User.class, 1L);
//사용자의 필드를 변경합니다.
user.setUsername("newUsername");
user.setEmail("newEmail@example.com");
//트랜잭션을 커밋하면 쓰기 지연이 반영됩니다.
transaction.commit();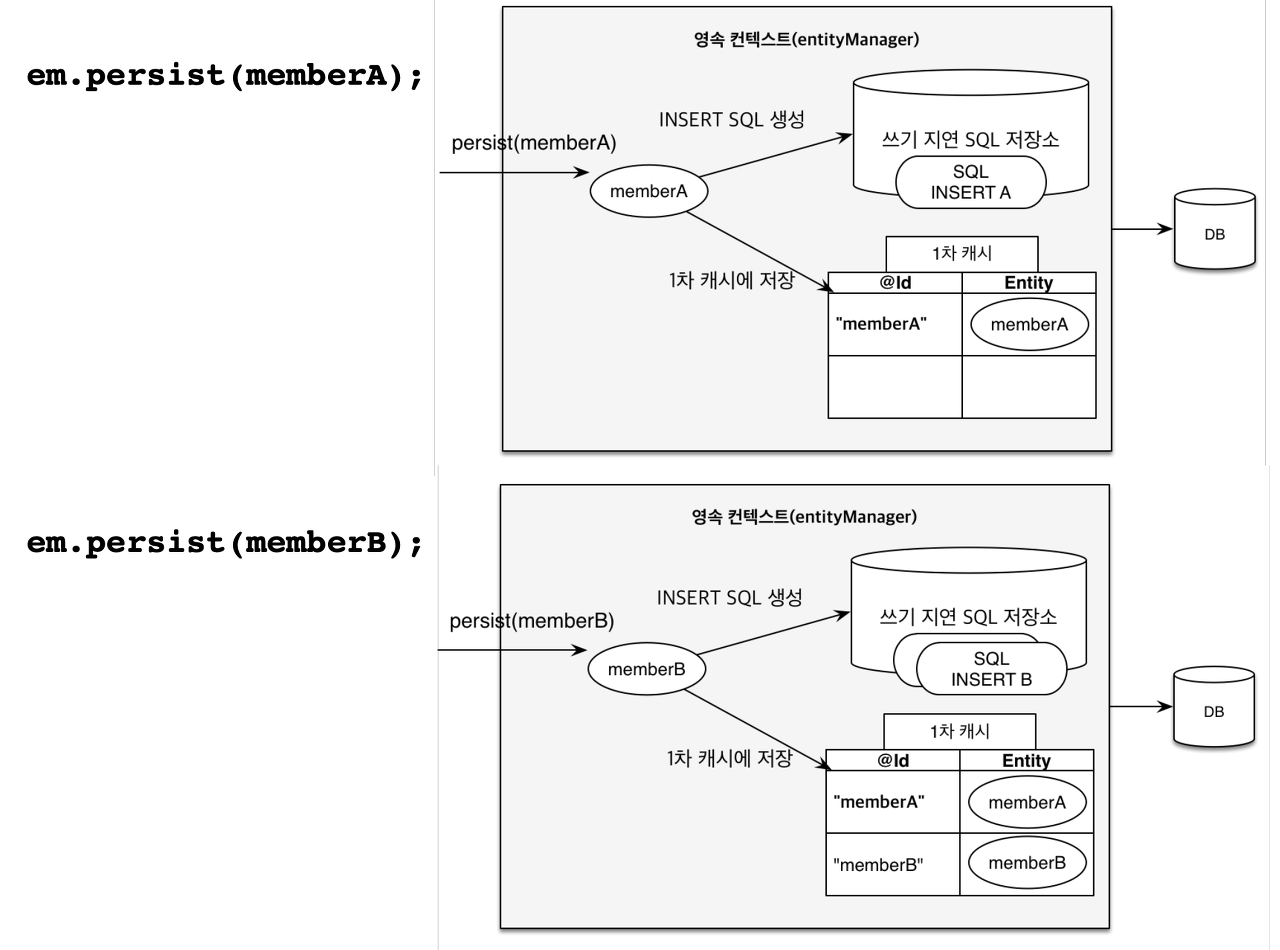

쓰기 지연 과정
- memberA의 insert 쿼리를 임시 저장소에 저장(DB에는 insert하지 않음)
- memberA 1차 캐시에 저장
- memberB의 insert 쿼리를 임시 저장소에 저장(DB에는 insert하지 않음)
- memberB 1차 캐시에 저장
- commit시 DB에 memberA, memberB insert
- 데이터베이스 트랜잭션을 커밋
1차 캐시(First-Level Cache)
- EntityManager가 관리하는 영속성 컨텍스트 내부에 존재하며 메모리 내의 첫 번째 캐시
- 엔티티 객체의 상태를 저장하고 쿼리 결과를 캐시
- 데이터베이스 접근 횟수를 줄이면 애플리케이션 성능을 획기적으로 개선할 수 있습니다.
- 이 캐시를 통해 같은 엔티티에 대한 반복적인 데이터베이스 조회를 피하고, 성능을 향상할 수 있습니다.
- 트랜잭션을 시작하고 종료할 때까지 1차 캐시가 유효합니다.

- 동작 원리
- 조회 시 1차 캐시에 데이터가 이미 있는지 확인하고, 데이터가 있으면 가져온다. (비교는 PK로 한다.)
- 1차 캐시에 데이터가 없다면, 데이터베이스에 데이터를 요청한다.
- 데이터베이스에서 받은 데이터를 다음에 재사용할 수 있도록 1차 캐시에 저장한다.
2차 캐시 (Second-Level Cache)
- 여러 영속성 컨텍스트 간에 공유되는 캐시로, 애플리케이션 전반에서 엔티티를 공유하고 재사용
- *참조: 영속성 컨텍스트 개수는 Entity 개수에 따라 할당됨
- 데이터베이스 쿼리 결과나 엔티티를 메모리에 캐시 하여 데이터베이스 조회 비용을 줄이고 성능을 향상
- 2차 캐시를 사용할 때 캐시 일관성과 동기화에 주의
- 여러 트랜잭션 간에 엔티티를 공유하고 데이터베이스 조회를 줄이는 데 사용

2차 캐시는 언제 사용하는지?
- 다수의 엔티티 매니저 사용 시: 여러 개의 엔티티 매니저가 동일한 데이터에 접근할 때, 2차 캐시를 사용하여 성능을 향상시킬 수 있습니다.
- 큰 규모의 읽기 작업이 필요한 경우: 읽기 작업이 많은 환경에서 2차 캐시를 사용하면 데이터베이스 부하를 줄일 수 있습니다.
- 데이터의 변경이 적은 경우: 데이터가 자주 변경되지 않고 읽기 중심의 환경에서 2차 캐시를 사용하면 성능 향상을 기대할 수 있습니다.
반대로 2차 캐시를 사용하지 말아야 하는 경우
- 데이터 변경이 자주 발생하는 경우: 데이터가 자주 변경되는 환경에서는 2차 캐시를 사용하면 캐시의 일관성 유지가 어려울 수 있습니다.
- 엔티티 간 연관관계가 복잡한 경우: 연관된 엔티티들 간의 복잡한 관계가 있을 때 2차 캐시를 사용하면 캐시의 관리가 어려울 수 있습니다.
결과
- JPA를 도입하여 쿼리의 작성이 없어 빠른 개발이 가능하였습니다. 그러나 MyBatis를 사용했을 때는 매번 SQL을 작성하는 번거로움이 있었습니다. 이렇게 쿼리 작성의 부담이 감소함으로써 개발자는 프로젝트에 집중할 수 있게 되었습니다.
- CRUD(Create, Read, Update, Delete) 작업을 자동화하여 개발 생산성을 크게 향상시켰으며 매서드 규칙에 맞추어 새로운 기능을 빠르게 개발할 수 있었습니다.
- JPA을 도입함으로써 Auction 서버 프로젝트는 다양한 데이터베이스와의 호환성을 제공할 수 있으며, 확장성과 유연성을 높일 수 있게 되었습니다.
- 또한, JPA를 사용하면 객체 간의 관계를 쉽게 관리하고 데이터베이스와의 불일치를 해결할 수 있습니다.
출처
- https://velog.io/@rainmaker007/Jpa-EntityManager-%EC%84%A4%EB%AA%85-%EC%98%81%EC%86%8D%EC%84%B1-%EC%BB%A8%ED%85%8D%EC%8A%A4%ED%8A%B8
- https://junghyungil.tistory.com/203
- https://junghyungil.tistory.com/140?category=943340
- https://kihwan95.tistory.com/4
- https://myhyem.tistory.com/24
- https://daram.tistory.com/265
'JAVA & Spring > Spring' 카테고리의 다른 글
| JPA EntityManager의 Thread-safe 이해하기 (0) | 2024.06.02 |
|---|---|
| JPA 구성요소와 기본 이해 (0) | 2023.09.18 |
| [Spring]DI(의존성 주입) (0) | 2022.04.14 |